简介
ARM架构
ARM架构(Advanced RISC Machine 更早称作Acorn RISC Machine)是一种基于精简指令集计算(RISC)的处理器架构,以其高效能和低功耗的特性在移动设备、嵌入式系统以及服务器等领域得到广泛应用。
ARM32架构
ARM32架构提供了16个通用寄存器(R0至R15),其中R15为程序计数器(PC)。ARM模式和Thumb模式共享这些寄存器,但由于指令长度不同,寄存器的访问方式也有所差异。
ARM32架构引入了三种模式:
- ARM模式: 适用于对性能要求较高的场景,如复杂计算和数据密集型应用。ARM模式使用32位指令集,指令大小为4字节,提供较强的计算能力。
- Thumb模式:适合内存和存储受限的设备,指令大小为2字节,能有效节省内存,提高存储效率。
- Thumb-2模式:结合ARM和Thumb指令,在执行效率与内存使用之间提供最佳平衡,广泛应用于需要平衡性能与资源消耗的嵌入式系统,指令大小为2或4字节。
ARM64架构
ARM64架构(也称为AArch64)是ARM架构的64位扩展,旨在提供更高的性能和更大的内存寻址能力。它定义了两种执行状态,以兼顾兼容性和现代计算需求:
AArch32状态
AArch32状态提供与经典ARMv7-A及更早32位ARM架构的兼容性,支持A32(ARM)或T32(Thumb/Thumb-2)指令集。A32指令固定为32位,而T32指令则包含16位和32位混合指令。AArch32状态适用于内存和计算需求较低的场景,尤其是对现有32位应用程序和操作系统具有兼容性要求的设备,常见于嵌入式系统和低功耗设备。
AArch64状态
AArch64是ARM64的原生64位执行状态,使用A64指令集,所有指令长度为32位(4字节)。AArch64提供64位宽的通用寄存器、更大的虚拟地址空间(通常为48位)以及增强的指令集,适合对计算能力和内存有较高要求的应用,如高性能计算、服务器、移动设备和桌面计算。
执行状态切换
ARM64架构支持在异常级别转换(如系统调用或中断时)时切换执行状态。根据目标异常级别的配置,处理器可以在支持AArch64的内核上同时运行64位(AArch64)和32位(AArch32)用户态应用程序,或在支持AArch32的内核上运行32位应用程序。这种机制确保操作系统可以灵活地处理不同架构的应用。
ARM指令集与产品命名规范
ARM 指令集架构(ISA)命名
ARMv3 – ARMv6
指令集命名规则: ARMv[n][variants][x(variants)]
组成部分:
- ARMv:固定前缀,表示 ARM 架构版本
- n:核心架构主版本号 (1-6)
- variants:(可选) 包含的变种/特性。表示该版本架构支持的可选功能扩展
- T: 支持 Thumb (16位) 指令集
- M:支持 长乘法指令 (32×32->64)
- E:支持 增强型 DSP 指令
- J: 支持 Jazelle (Java bytecode 加速)
- SIMD:支持 ARM 媒体功能扩展 (早期 SIMD)
- [x(variants)]: (可选) 排除的变种。以
x开头,后面紧跟一个或多个字母,表示该特定实现或配置中不包含这些在基础版本中可能存在的特性
示例:
- ARMv5T: ARMv5 架构,支持 Thumb 指令集。
- ARMv5TE: ARMv5 架构,支持 Thumb 和增强型 DSP 指令。
- ARMv5TxM: ARMv5 架构,支持 Thumb (T),但不支持长乘法指令 (xM)。 (基于 ARMv5T 的一个特定配置)。
- ARMv6: ARMv6 基础架构。
- ARMv6K: ARMv6 架构,包含特定扩展 (K 通常表示支持多核同步原语)。
ARMv7 及之后命名规则
指令集命名规则: ARMv[n][Profile][.minor][optional_extensions]
组成部分:
- ARMv: 固定前缀,表示 ARM 架构版本
- n:核心架构主版本号 (7-X)
- Profile:必须指定的核心配置文件。定义了架构的根本目标和特性集
- A (Application profile) :
- 面向运行复杂操作系统(Linux, Android, Windows, macOS)的应用处理器
- 支持基于内存管理单元 (MMU) 的虚拟内存系统架构 (VMSA)
- 支持A64、A32、T32指令集
- R (Real-time profile) :
- 面向需要硬实时性能的嵌入式系统。
- 支持基于内存保护单元 (MPU) 的受保护内存系统架构 (PMSA)
- 支持基于 MMU 的可选 VMSA
- 支持A64、A32、T32指令集
- M (Microcontroller profile) :
- 面向深入嵌入式和微控制器应用,强调超低功耗,小面积,易用性。
- 实现了专为低延迟中断处理而设计的程序员模型,具有寄存器的硬件堆栈,并支持使用高级语言编写中断处理程序
- 实现了实时处理器配置文件(R-profile)保护内存系统架构(PMSA)的一个变体
- 支持 Thumb-2(T32)指令集的一个变体
- A (Application profile) :
- .minor:(可选) 次要版本号。表示在该主版本和 Profile 下的增量功能扩展或修订
示例
- ARMv7-A: ARMv7 应用处理器配置文件。
- ARMv8-A: ARMv8 应用处理器配置文件 (引入 64位 AArch64)。
- ARMv8-R: ARMv8 实时处理器配置文件。
- ARMv8.1-M: ARMv8-M 的第 1 次功能扩展 (如新增指令、增强安全)。
ARM 处理器系列命名
ARMv3 – ARMv6
处理器命名规则:ARM{x}{y}{z}{suffixes}
组成部分:
- x:处理器家族代号/世代 (7-X)
- y:存储管理/保护单元类型(例如MMU或MPU数量)
- z:Cache 配置Cache大小或结构)
- suffixes:后缀字母 (可选,可组合)
- T:支持 Thumb 指令集
- D:支持 片上调试 (On-chip Debug)
- M:支持 快速乘法器 (32×32->32 或 32×32->64)
- I:支持 EmbeddedICE 宏单元,提供嵌入式跟踪调试 (JTAG 调试)
- E:支持 增强型 DSP 指令
- J:支持 Jazelle 直接 Java bytecode 执行
- F:包含 向量浮点单元 (VFP)
- -S:表示该处理器设计是 可综合的 (Synthesizable),以 RTL (如 Verilog, VHDL) 形式交付给芯片厂商,而非硬核。
ARMv7 及之后命名规则
自ARMv7架构起,ARM公司彻底改革命名体系,启用 Cortex 作为统一品牌。
| 系列 | 目标市场 | 核心特性 | 典型产品 |
|---|---|---|---|
| Cortex-A | 高性能应用处理器 | 支持虚拟内存(MMU)、多核/高频设计、运行Linux/Android等复杂OS | Cortex-A53/A77/A715 |
| Cortex-R | 实时嵌入式系统 | 硬实时响应、高可靠性(ECC/锁步核)、内存保护(MPU),适用于汽车制动/工业控制 | Cortex-R5/R52/R82 |
| Cortex-M | 微控制器(MCU) | 超低功耗、精简指令集(Thumb-2)、无MMU,替代传统8051/ARM7 | Cortex-M0+/M4/M33 |
寄存器
ARM32
| 寄存器 | 用途 |
|---|---|
| R0-R3 | 参数寄存器:用于传递函数的前四个参数(如果有更多参数,会通过栈传递), 除此之外 函数返回值通常使用r0寄存器。 |
| R4-R7 | 保存寄存器:通常用于存储局部变量或中间结果,函数调用时不会被修改。 |
| R8-R12 | 临时寄存器:通常用于临时存储数据,函数调用时可以被修改。 |
| R13 | 栈指针 (Stack Pointer as SP):指向当前栈的顶部,用于管理堆栈。 |
| r14 | 链接寄存器 (Link Register as LR):存储函数调用的返回地址。 |
| r15 | 程序计数器 (Program Counter as PC):指向当前执行指令的地址,用于控制程序的执行流程。 |
| cpsr | 当前程序状态寄存器 (Current Program Status Register):包含条件标志(如零标志、负标志、溢出标志等),以及控制状态和中断禁用状态。 |
ARM64
| 寄存器 | 用途 |
|---|---|
| x0 – x7 | 参数寄存器:用于传递函数的前八个参数(如果有更多参数,会通过栈传递), , 除此之外 函数返回值通常使用x0寄存器。。 |
| x8 | 返回值寄存器:用于函数返回值。通常,函数的返回值存储在x0寄存器中,但当返回多个值时,x8也可能用于额外的返回值。 |
| x9 – x15 | 保存寄存器:这些寄存器通常用于存储局部变量或中间结果,在函数调用时不被修改。 |
| x16 – x17 | 链接寄存器 (LR) 和中间结果:x16用于操作系统/异常处理的链接寄存器(例如异常返回地址),x17通常作为中间结果寄存器。 |
| x18 | 平台特定寄存器:根据平台的不同,x18可以作为操作系统或平台的特定用途寄存器。 |
| x19 – x28 | 保存寄存器:这些寄存器用于保存局部变量,在函数调用时不会被修改。 |
| x29 | 帧指针寄存器 (FP):指向当前函数栈帧的基地址,用于栈操作。 |
| x30 | 链接寄存器 (LR):存储函数调用的返回地址。 |
| PC | 程序计数器 (PC):指向当前执行的指令,ARM64架构中,x31也叫pc寄存器,用于控制程序的执行流。 |
| sp | 栈指针 (SP):指向当前栈的顶部,用于堆栈管理。与x29(帧指针)一起用于栈操作。 |
| nzcv | 程序状态寄存器 (CPSR):包含当前程序的条件标志(如零标志、负标志、溢出标志等),用于控制程序状态。 |
调用约定
ARM32
在 ARM32 架构下,常见的调用约定为 AAPCS (ARM Architecture Procedure Call Standard)。
参数传递:
- 前四个参数通过寄存器传递:
r0–r3。 - 超过四个参数的部分通过栈传递。
- 对于浮点参数,前四个浮点参数通过
s0–s3(如果有更多的浮点参数,继续通过栈传递)。
返回值:
- 返回值通常存放在
r0寄存器中。 - 如果返回值是浮点数,通常会通过
s0寄存器返回。
栈:
- 栈对齐:栈通常需要按 8 字节对齐。
- 在函数调用前,调用者需要保存寄存器
r4–r11(通用寄存器)以及lr(链接寄存器),如果需要使用这些寄存器。 - 被调用者函数保存
r4–r11和lr,并在返回之前恢复它们。
栈指针:
- 栈指针通常是
sp,但栈指针在某些情况下可能会有额外的对齐要求。
调用约定总结:
- 参数:
r0–r3(最多四个整数参数),栈传递额外参数。 - 返回值:
r0(整数返回值),s0(浮点返回值)。 - 寄存器保存:调用者保存
r4–r11,被调用者保存r4–r11和lr。
ARM64
在 ARM64 架构下,常见的调用约定为 AArch64 Procedure Call Standard (AAPCS64)
参数传递:
- 前八个参数通过寄存器传递:
x0–x7。 - 如果有更多的参数,剩余的参数通过栈传递。
- 对于浮点参数,前八个浮点参数通过
v0–v7(如果有更多的浮点参数,继续通过栈传递)。
返回值:
- 返回值通常存放在
x0寄存器中(对于整数或指针类型)。 - 如果返回值是浮点数,通常会通过
v0寄存器返回。
栈:
- 栈对齐:栈通常需要按 16 字节对齐(相较于 ARM32 的 8 字节对齐)。
- 在函数调用前,调用者需要保存
x19–x29(通用寄存器)以及lr(链接寄存器),如果需要使用这些寄存器。 - 被调用者函数保存
x19–x29和lr,并在返回之前恢复它们。
栈指针:
- 栈指针通常是
sp,栈对齐要求为 16 字节。
调用约定总结:
- 参数:
x0–x7(最多八个整数参数),栈传递额外参数。 - 返回值:
x0(整数返回值),v0(浮点返回值)。 - 寄存器保存:调用者保存
x19–x29,被调用者保存x19–x29和lr。
逆向原生
在网上找到一个排序算法,我们以这个程序为例。
常见指令
| 指令 | 类型 | 操作数 | 说明 |
|---|---|---|---|
| push | 堆栈操作 | {reg_list} | 将寄存器列表中的值压入堆栈 |
| pop | 堆栈操作 | {reg_list} | 从堆栈中弹出数据到寄存器列表 |
| sub | 算术操作 | Rd, Rn, #imm 或 sp, #imm | 从寄存器Rn减立即数或直接修改栈指针 |
| add | 算术操作 | Rd, Rn, Op2 | 将寄存器Rn和操作数(寄存器/立即数)相加 |
| movs | 算术操作 | Rd, #imm 或 Rd, Rm | 传送立即数/寄存器值到Rd并更新标志位 |
| adds | 算术操作 | Rd, Rn, Op2 | 加法操作并更新标志位 |
| subs | 算术操作 | Rd, Rn, Op2 | 减法操作并更新标志位 |
| lsls | 移位操作 | Rd, Rm, #imm 或 Rd, Rm, Rs | 逻辑左移操作并更新标志位 |
| cmp | 比较操作 | Rn, Op2 | 比较两个操作数并更新标志位 |
| ble | 跳转指令(条件) | label | 若小于或等于则跳转(依赖标志位) |
| b | 跳转指令 | label | 无条件跳转到标签 |
| bx | 跳转指令(分支) | Rm | 分支并交换指令集状态到寄存器地址(如bx lr用于函数返回) |
| str | 存储操作 | Rt, [Rn, #offset] | 将寄存器值存入内存地址 |
| ldr | 加载操作 | Rt, [Rn, #offset] | 从内存地址加载数据到寄存器 |
| nop | 空操作 | – | 不进行任何操作(用于延时或占位) |
反编译
bubbleSort XREF[2]: Entry Point(*), main:00010762(c)
00010640 80 b4 push {r7}
00010642 87 b0 sub sp,#0x1c
00010644 00 af add r7,sp,#0x0
00010646 78 60 str array,[r7,#local_1c]
00010648 39 60 str len,[r7,#0x0]=>local_20
0001064a 00 23 movs r3,#0x0
0001064c fb 60 str r3,[r7,#i]
0001064e 34 e0 b LAB_000106ba
LAB_00010650 XREF[1]: 000106c2(j)
00010650 00 23 movs r3,#0x0
00010652 3b 61 str r3,[r7,#j]
00010654 27 e0 b LAB_000106a6
LAB_00010656 XREF[1]: 000106b2(j)
00010656 3b 69 ldr r3,[r7,#j]
00010658 9b 00 lsls r3,r3,#0x2
0001065a 7a 68 ldr r2,[r7,#local_1c]
0001065c 13 44 add r3,r2
0001065e 1a 68 ldr r2,[r3,#0x0]
00010660 3b 69 ldr r3,[r7,#j]
00010662 01 33 adds r3,#0x1
00010664 9b 00 lsls r3,r3,#0x2
00010666 79 68 ldr len,[r7,#local_1c]
00010668 0b 44 add r3,len
0001066a 1b 68 ldr r3,[r3,#0x0]
0001066c 9a 42 cmp r2,r3
0001066e 17 dd ble LAB_000106a0
00010670 3b 69 ldr r3,[r7,#j]
00010672 9b 00 lsls r3,r3,#0x2
00010674 7a 68 ldr r2,[r7,#local_1c]
00010676 13 44 add r3,r2
00010678 1b 68 ldr tmp,[tmp,#0x0]
0001067a 7b 61 str tmp,[r7,#local_c]
0001067c 3b 69 ldr tmp,[r7,#j]
0001067e 01 33 adds tmp,#0x1
00010680 9b 00 lsls tmp,tmp,#0x2
00010682 7a 68 ldr r2,[r7,#local_1c]
00010684 1a 44 add r2,tmp
00010686 3b 69 ldr tmp,[r7,#j]
00010688 9b 00 lsls tmp,tmp,#0x2
0001068a 79 68 ldr len,[r7,#local_1c]
0001068c 0b 44 add tmp,len
0001068e 12 68 ldr r2,[r2,#0x0]
00010690 1a 60 str r2,[tmp,#0x0]
00010692 3b 69 ldr tmp,[r7,#j]
00010694 01 33 adds tmp,#0x1
00010696 9b 00 lsls tmp,tmp,#0x2
00010698 7a 68 ldr r2,[r7,#local_1c]
0001069a 13 44 add tmp,r2
0001069c 7a 69 ldr r2,[r7,#local_c]
0001069e 1a 60 str r2,[tmp,#0x0]
LAB_000106a0 XREF[1]: 0001066e(j)
000106a0 3b 69 ldr tmp,[r7,#j]
000106a2 01 33 adds tmp,#0x1
000106a4 3b 61 str tmp,[r7,#j]
LAB_000106a6 XREF[1]: 00010654(j)
000106a6 3a 68 ldr r2,[r7,#0x0]=>local_20
000106a8 fb 68 ldr tmp,[r7,#i]
000106aa d3 1a subs tmp,r2,tmp
000106ac 01 3b subs tmp,#0x1
000106ae 3a 69 ldr r2,[r7,#j]
000106b0 9a 42 cmp r2,tmp
000106b2 d0 db blt LAB_00010656
000106b4 fb 68 ldr tmp,[r7,#i]
000106b6 01 33 adds tmp,#0x1
000106b8 fb 60 str tmp,[r7,#i]
LAB_000106ba XREF[1]: 0001064e(j)
000106ba 3b 68 ldr tmp,[r7,#0x0]=>local_20
000106bc 01 3b subs tmp,#0x1
000106be fa 68 ldr r2,[r7,#i]
000106c0 9a 42 cmp r2,tmp
000106c2 c5 db blt LAB_00010650
000106c4 00 bf nop
000106c6 00 bf nop
000106c8 1c 37 adds r7,#0x1c
000106ca bd 46 mov sp,r7
000106cc 5d f8 04 7b pop.w r7=>local_4
000106d0 70 47 bx lr
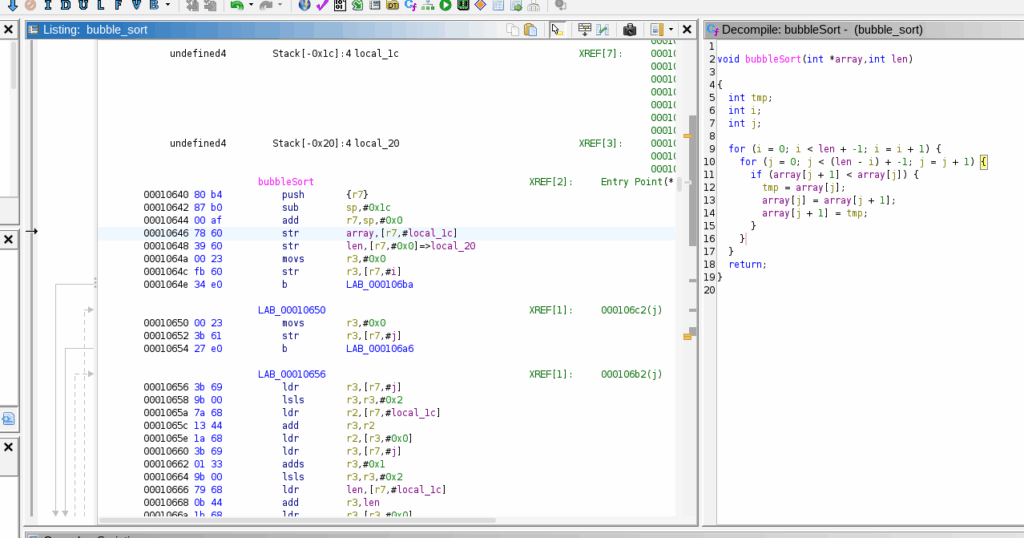
通过ghidra反汇编后,即使不参考符号名,单看算法逻辑也一眼就能看出到了是冒泡排序算法。
安全防范
Virbox Protector 提供全面的 ARM 程序安全防护,主要包括代码虚拟化和代码混淆,有效防止逆向分析。它通过导入表保护和内存保护(防篡改与防Dump),确保程序的敏感数据和代码不被篡改或提取分析。此外,Virbox Protector 还具备压缩功能,减小程序体积并增加静态分析的难度,以及强效的调试器检测,主动识别并阻止调试,防止程序被动态调试和破解。最后,移除调试信息(如符号剥离)进一步提升了程序的安全性。总体而言,Virbox Protector 通过多层次的保护机制,显著增强了 ARM 程序的抗破解能力。
